Проиндексированные страницы сайта в Google
Одним из ключевых условий получения трафика с поисковых систем является наличие сайта (и его страниц) в их базах данных. Поэтому вебмастеру важно знать о проиндексированных страницах сайта. В своей статье я предлагаю Вашему вниманию не только пошаговую инструкцию решения данной задачи, но и ряд простых и полезных инструментов: букмаркле для получения списка URL-адресов из выдачи Google, php-парсеры файлов Sitemaps и экспорта Blogger, а также php-скрипт для сравнения списков и выявления отсутствующих в SERP'е поисковой системы страниц сайта.
Шаг 1: список проиндексированных страниц сайта в Google. Для того чтобы узнать, какие страницы сайта уже проиндексированы поисковой системой, можно воспользоваться специальным оператором языка запросов site, например:
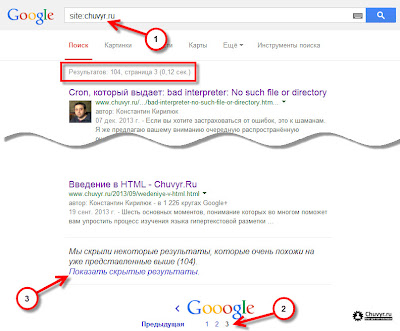
Обращаю Ваше внимание на то, что (по умолчанию) поисковая система Google выдаст лишь те страницы сайта, которые учитываются в поиске. Страницы похожие на уже представленные в выдаче или закрытые для индексации в robots.txt будут скрыты.
Шаг 2: все проиндексированные страницы сайта в Google. Для того чтобы получить весь список проиндексированных страниц сайта, Вам нужно перейти на последнюю страницу выдачи и кликнуть ссылку «Показать скрытые результаты».
Шаг 3: сбор URL-адресов проиндексированных страниц сайта в Google. Для того чтобы получить только список URL-адресов, не тратя времени на копирование каждого из них, я предлагаю Вашему вниманию простой букмарклет (javascript закладка для браузера), который выполнит эту задачу за Вас. Его код выглядит следующим образом:
var u = '';
/* обработка элементов выдачи по классу g */
[].forEach.call(document.getElementsByClassName('g'), function(g) {
/* исключение из обработки */
if (
( (g.hasAttribute('id')) && (g.id == 'imagebox_bigimages') ) || // блок с картинками
( g.getElementsByClassName('rc').length == 0 ) // блок с адресами
) { } else {
u+= g.getElementsByClassName('r')[0].getElementsByTagName('a')[0].href + '<br>';
}
});
/* выводим результат в новом окне/вкладке */
var w = window.open('', '_blank');
w.document.write(u);
Как Вы видите, скрипт обрабатывает страницу выдачи и собирает URL-адреса результатов, которые выводятся в отдельно окне или вкладке браузера. Но как им пользоваться?
- Перенесите ссылку: gSERP URLs – на панель закладок вашего браузера.
- Выполните пункты 1 и 2 инструкции.
- Для каждой страницы выдачи кликните закладку и скопируйте списки в один текстовый файл, например: serp.txt
К слову, Вы можете выводить на одной странице выдачи сразу по 50, или даже 100, результатов, что регулируется в соответствующих настройках поисковой системы. Здесь я рекомендую использовать специально заточенные под это дело поисковые плагины для браузеров, которые Вы можете найти на сайте opensearch.c3h.ru.
Шаг 4: сбор URL-адресов страниц сайта из Sitemaps файла или XML-экспорта Blogger. Теперь у нас есть список URL-адресов проиндексированных в Google страниц сайта. Но с чем его сравнивать? Очевидно, что нам нужен список URL-адресов страниц с самого сайта. Как его получить? Вариантов тут много. Я же остановлюсь лишь на двух из них.
Самый простой вариант, это конечно обработка файла Sitemaps, особенно если он сгенерирован в текстовом формате. Несколько сложнее, если он сгенерирован в XML-формате. В этом случае я предлагаю Вашему вниманию простенький php-парсер Sitemap с использованием SimpleXML. Как им пользоваться?
- Скачать php-парсер Sitemap можно по этой (Google Диск) или этой (Яндекс.Диск) ссылкам.
- Разархивируйте и скопируйте файл скрипта на сервер.
- Откройте файл скрипта в текстовом редакторе (в том же «Блокнот») и пропишите, в качестве значения переменной
$url, URL-адрес файла sitemap.xml. Не забудьте сохранить файл скрипта. - Обратитесь к скрипту на сервере через браузер.
Результатом работы скрипта будет список URL-адресов страниц сайта в нужном нам виде. Сохраните этот список как обычный текстовый файл, например: site.txt.
На самом деле у блогов на Blogger тоже есть файл sitemap.xml. Просто я его заметил не сразу, ведь для блогов с персональным доменом при обращении к нему мы получим 404 ошибку. Так или иначе, но у нас есть возможность экспортировать блог в XML-файл. Сделать это можно, перейдя на страницу: Настройки > Другое – в панели управления блогом и кликнув ссылку «Экспорт блога».
экспорт блога blogger
Для его парсинга и формирования только списка URL-адресов я предлагаю Вашему вниманию простенький php-парсер экспорта Blogger с использованием SimpleXML. Как им пользоваться?
- Скачать php-парсер экспорта Blogger можно по этой (Google Диск) или этой (Яндекс.Диск) ссылке.
- Разархивируйте и скопируйте файл скрипта на сервер.
- Туда же скопируйте и файл экспорта блога с Blogger, он может выглядеть следующим образом: blog-03-26-2014.xml.
- Откройте файл скрипта в текстовом редакторе (в том же «Блокнот») и пропишите, в качестве значения переменной $url, относительный адрес файла экспорта, например:
$url = '/2014/04/blog-03-26-2014.xml'. Не забудьте сохранить файл скрипта. - Обратитесь к скрипту на сервере через браузер.
Результатом его выполнения будет список URL-адресов только сообщений (!) блога на Blogger в нужном нам виде. Сохраните этот список как обычный текстовый файл, например: site.txt.
Шаг 5: сравнение результатов индекса Google и страниц сайта. По сути, у нас должно получится два списка URL-адресов страниц сайта в SERP (serp.txt) и на сайте (site.txt) в текстовом виде. Теперь надо выявить какие страницы присутствую в индексе Google, а какие нет.
Здесь я снова предлагаю Вам небольшое и простое решение на PHP. Как им пользоваться?
- Скачать php-скрипт сравнения списков URL-адресов можно по этой (Google Диск) или этой (Яндекс.Диск) ссылке.
- Разархивируйте и скопируйте файл скрипта на сервер.
- Туда же скопируйте и файлы списков URL-адресов страниц сайта в SERP (serp.txt) и на сайте (site.txt).
- Откройте файл скрипта в текстовом редакторе (в том же «Блокнот») и пропишите, в качестве значения переменной
$url_serp, относительный адрес файла со списком URL-адресов страниц сайта в SERP (serp.txt), а в качестве значения переменной$url_site, относительный адрес файла со списком URL-адресов страниц на сайте (site.txt). Не забудьте сохранить файл скрипта. - Обратитесь к скрипту на сервере через браузер.
Результатом его выполнения будет список сравнения, состоящий из ссылок на страницы сайта [site] и проверки наличия страницы в выдаче [serp] через оператор info, а также самого URL-адреса и статуса проверки:
- OK – страница присутствует в выдаче и на сайте.
- NOT in SERP – страница присутствует на сайте, но её нет в выдаче.
- NOT on SITE – страница присутствует в выдаче, но её нет на сайте.
Учтите, что список URL-адресов, составленный на основе экспорта из Blogger, содержит только страницы сообщений блога.
Возможно, в сети Интернет есть и готовое решение данной задачи, оформленное в полноценный софт, но мне о нём не известно. Также стоит отметить, что всё перечисленное можно в значительной степени автоматизировать, подключив тот же API для сбора страниц в Google и т.д. Я же предложил всё это в простом и доступном виде. На этом у меня всё. Спасибо за внимание. Удачи!
Короткая ссылка: http://goo.gl/U6UVne